MLops-5 글에 이어서 이번에는 '스키마 추론과 스키마 환경'에 대해서 이어서 정리를 해보려고 한다.
- 데이터 검증 ( TFDV )
- 데이터 검증 TFDV
- 스키마 추론과 스키마 환경
- 데이터 드리프트 및 스큐
- 스키마 추론
- tfdv.infer_schema를 사용해서 데이터에 대한 스키마를 생성할 수 있다.
- csv에서 학습데이터에 대한 스키마를 뽑을 수 있다.
- 피쳐들이 자료형인지(int, float..) 알아서 정리를 해준다. 카테고리도 마찬가지로 정리가 된다.
- TFDV를 통해서 스키마에 대한 추론을 한 다음에, 스키마가 어떻게 구성되어 있는지를 하나의 스키마로 출력을 할 수 있다.
-
schema = tfdv.infer_schema(statistics=train_stats) tfdv.display_schema(schema=schema) 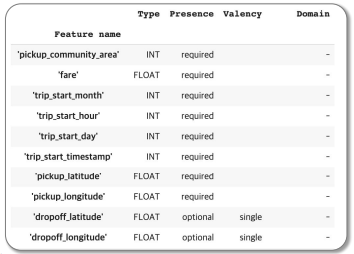
schema를 한눈에 정리한 이미지 - 평가 데이터의 오류 확인
-
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA) tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats, lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
- 두 개의 데이터 통계치를 같이 넣어주면은 tfdv가 두가지 데이터를 한번에 비교를 해준다.
- 파란색이 평가데이터, 노란색이 학습데이터인데 각각의 평균, 분포를 볼 수 있다.
- 시각화를 하다보면 분포가 많이 다른 경우를 볼 수 있다. 분포가 쏠려있으면 학습에 대한 성능이 낮아질 수 있다. tfdv를 통해서 눈으로 확인할 수 있다. -> 데이터를 깊이 파봐야 모델에 대한 객관적인 문제점을 진단할 수 있다.
- 평가 데이터의 이상 데이터 확인
-
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema) tfdv.display_anomalies(anomalies) 
- 만든 스키마를 가져와서 평가를 해보는 것이다. statistics를 스키마를 기반으로 평가를 할 수 있다.
- 위를 통해 anomalies을 판단하게 된다.
- company라는 필드에 학습데이터에서는 없었지만 새로생긴 company가 확인이 된 것을 볼 수 있다. 이러한 것들이 성능을 떨어트리는 것이다.
- panyment_type도 prcard라는 것이 학습데이터에서 없었는데 생긴 것을 확인 할 수 있다.
- 위의 작업을 통해서 학습데이터와 평가데이터를 비교해서 평가데이터에 이상 데이터가 있는지 체크할 수 있다.
-
- 스키마의 평가 이상 수정
- 위에서 이상 데이터를 확인했다.
- 이상이 실제로 데이터 오류를 나타내는 경우 기본 데이터를 수정해야 한다. 그렇지 않으면 평가 데이터 세트에 값을 포함하도록 스키마를 업데이트 할 수 있다.
-
company = tfdv.get_feature(schema,'company') company.distribution_constraints.min_domain_mass = 0.9 payment_type_domain = tfdv.get_domain(schema,'payment_type') payment_type_domain.value.append('Prcard') updated_animalies = tfdv.validate_statistics(eval_stats, schema) tfdv.display_anomalies(updated_anomalies) - 위의 작업을 통해서 company값과 Prcard값에 대해서 변경 및 추가를 해준 후, 업데이트(변경된 스키마로)를 해준다.
- 스키마를 업데이트 해주면 'No anomalies found'라는 값이 나오면 이상을 찾을 수 없다고 뜬다.
- 스키마 환경
- 이 예제에서 'Serving' 데이터 셋을 분리했어서 이것도 확인해야한다.
- 기본적으로 파이프 라인의 모든 데이터 셋은 동일한 스키마를 사용하지만 예외가 있는 경우도 많다.
- schema의 피처는 defalut_environment, in_environment및 not_in_environmen를 사용할 수 있다.
-
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA) serving_anomalies = tfdv.validate_statistics(serving_stats, schema) tfdv.display_anomalies(serving_anomalies) 
- Serving 데이터 셋의 anomalies를 확인 하는 것이다. 여기서 'tips'이라는 피쳐가 빠져있다는 것을 확인했으므로, 추가해줘야한다.
-
options = tfdv.StatsOptions(schema = schema, infer_type_from_schema = True) serving_stats = tfdv.tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options = options) serving_anomalies = tfdv.validate_statistics(serving_stats, schema) tfdv.display_anomalies(serving_anomalies) -
schema.default_environment.append('TRAINING’) schema.default_environment.append('SERVING’) tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING’) serving_anomalies_with_env = tfdv.validate_statistics( serving_stats, schema, environment='SERVING’) tfdv.display_anomalies(serving_anomalies_with_env) - 위의 작업을 통해 'tips'라는 피쳐는 'Serving'타입에는 사용되지 않는다고 처리한다. serving에서 anomalies가 없다는 것을 확인 할 수 있다.
- tfdv.infer_schema를 사용해서 데이터에 대한 스키마를 생성할 수 있다.
'공부 > MLOps' 카테고리의 다른 글
| MLops - 6. 도커 & 쿠버네틱스 (0) | 2022.03.01 |
|---|---|
| MLOps - 5 (TFDV) (0) | 2022.01.23 |
| MLOps - 4 (0) | 2022.01.06 |
| MLOps - 3 (0) | 2022.01.03 |
| MLOps - 2 (0) | 2021.12.12 |


